华为软件精英挑战赛
1. 摘要
本文主要介绍2018华为软件精英挑战赛的一个简单实现,不注重算法得分高低,只注重完成数据从输入、预处理、算法实现和数据输出过程的实现,所以本文并没有太多参考价值。
PS:
本文实现的代码仓库链接
2018华为软件精英挑战赛介绍
如果上述赛题介绍链接失效,请转至本地网页文件
2.总体思路

以天为时间间隔对数据进行预测。
3.读入数据与数据解析
读入的文件有两个,分别是训练数据文件和input file。
训练数据文件的读入与解析
原始数据是直接从文件中读取的list类型的str数据,利用正则表达式从list中解析出flavorn、日期和在当前日期的虚拟机总量三个数据,将解析出来的数据存到字典中,字典的j结构为:{key: vm_type, value: {key: date, value:numbers}。
其中匹配flavor类型和日期的正则表达式分别为:pattern = re.compile(r’(?<=flavor)\d+\b’) #匹配flavor后的数字
pattern = re.compile(r”(\d{4}-\d{1,2}-\d{1,2})”) #匹配”Y-M-D”格式的日期并且统计每种类型的flavor在每个日期出现的总次数,最终返回训练数据的字典。
input file的读入与解析
读入input file,利用正则表达式解析出物理服务器CPU、MEM和硬盘大小等数据,以及要预测日期的起始时间和要优化的类型。以上解析过程通过InputFile类来实现。
至此,完成文件的读入和解析。
4.预处理数据
预处理数据主要是针对训练数据,将训练数据中的离群值和异常值剔除掉。这里使用一个常用的方法—3σ准则进行数据预处理。
3σ准则简而言之认为数据分布在(μ-3σ,μ+3σ)区间的概率为0.9973,所以当数据超出这个区间即可认为该数据是异常值。3σ准则针对正态或近似正态分布的样本数据处理,其中σ代表标准差,μ代表均值。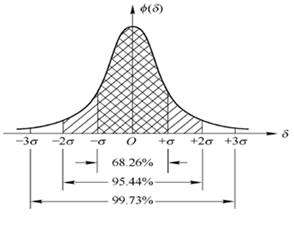
5.预测过程
通过绘制原始数据的折线图(后面章节会讲到数据可视化),可以发现训练数据是稀疏的时间序列数据,对此类数据进行预测,比较合适的事LSTM模型,但是由于比赛要求不能使用第三库,所以要用LSTM只能自己动手写神经网络的代码,这样工作量太大。所以使用最简单的最小二乘法进行预测。再次强调本代码不注重比赛得分,只是完成整个过程的实现。
最小二乘法实现的代码参考此处:click here
由于该代码在求解过程中使用了numpy库中的函数求解线性方程组:
self.solver = np.linalg.solve(matA, matB)
所以需要自己实现线性方程组的求解,参考此处代码:click here,实现线性方程组的求解。
以上代码在predictor.py中的predict_func函数完成,并且可以修改参数调整拟合的阶次,至此完成预测阶段。
6.分配过程
分配过程是一个组合优化的过程,本问题可以看成背包问题,解决此类问题的方法有很多:遗传算法、模拟退火算法等,这里采用比较容易实现的模拟退火算法进行求解。模拟退火算法参考此C++的实现,改写为python实现。
7.数据输出
完成分配过程后,将要输出的数据按照比赛输出数据的要求进行格式化处理,此功能的实现方法在OutputFile类中。
8.数据可视化
比赛要求不能使用第三方库,但是在观察数据特征和拟合结果时,可以使用matplotlib进行数据可视化,在提交代码的时候注释掉可视化的代码即可。本工程有两处可视化数据的地方,一处在predictor.py中调用data_visualize(train_data)函数,将训练数据以日期格式为横轴绘图。另一处在predictor.py中的predict_func函数中调用如下函数:
draw_predict(x_, y_, x1_, y1_, type_=’’,title=’Data Visualization’)`