内容说明
主要介绍一篇使用深度学习方法去实现Motion Planning的论文,并将作者开源的实现代码在本地进行复现,复现过程中涉及到Docker的使用,Colaboratory和Kaggle Kernel环境的使用等内容。主要内容包括两部分:
- 介绍论文Motion Planning Networks的主要内容
- 在本地Docker pytorch环境中利用作者的开源代码和提供的Simple 2D情况的数据集,训练模型,并测试模型在2维情况下Motion Planning的效果,此外该部分还包括如下内容:
- Docker容器中GUI程序的运行
- 在Google Colaboratory环境中训练该模型
- 在Kaggle Kernel环境中训练该模型
测试主机的环境是:
- 系统:Ubuntu16.04
- 显卡:1060 6G
1.Paper: Motion Planning Networks(arxiv,github)
1.1 摘要
随着运动规划维度的增加,RRT、A、D*等算法效率都将降低,本文提出了一种不论障碍物形状,端对端生成无碰撞路径的网络—Motion Planning Networks,简称MPNet
MPNet包含如下结构:
- 一个Contractive Autoencoder(收缩式自动编码器,CAE),对工作空间进行编码
- 一个前馈神经网络,该神经网络使用编码的工作空间、起始和目标点配置,端对端生成可行的运动轨迹,供机器人进行跟踪
作者测试了质点、刚体、7自由度机械臂在2D和3D环境下的规划问题,结果表明MPNet效率很高,且泛化能力很强。MPNet的运算时间始终小于1秒,明显低于现有的最先进的运动规划算法。此外,在一个场景训练的MPNet,可以借助少量数据通过迁移学习,快速适应新场景。
1.2 简介
机器人运动规划意义重大,应用广泛。开发了很多计算效率高的基于采样的规划算法—RRT,RRT,P-RRT。
本文提出了一种基于深度神经网络(DNN)的迭代运动规划算法—MPNet。
MPNet由两部分构成:
- 障碍物空间编码器——Contractive Autoencoder:将障碍物点云编码至低维隐空间(latent space)
- 路径规划器——前馈神经网络:在给定t时刻机器人的配置、目标点配置和障碍物编码后的隐空间时,预测t+1时刻机器人的配置
经过训练后,MPNet可以与新的双向迭代算法结合使用,来生成可行的轨迹。
1.3 神经网络在Motion Planning相关工作
- Hopfield网络
- Deep Reinforcement Learning
- Lightning Framework
1.4 问题定义
设$Q$表示长度为$N(N \in \mathbb{N})$的的有序表,序列$\{ q_i = Q(i) \}_{i \in \mathbb{N}}$表示从$i \in \mathbb{N}$到$Q$中第$i$个元素的映射。并且论文中$Q(end)$和$Q.length()$分别表示集合$Q$的最后一个元元素和集合中元素的个数。
设$X \subset \mathbb{R}^d$表示给定的状态空间,$d$是状态空间的维数,且$d \geq 2$,障碍物空间和非障碍物空间分别定义为$X_{obs} \subset X$, $X_{free} = X \backslash X_{obs}$。设初始状态为$x_{init} \in X_{free}$,目标区域为$X_{goal} \subset X_{free}$
设有序表$\tau$表示一条非负和非零长度的路径。如果路径$\tau$连接起$x_{init}$和$x \in X_{goal}$,则该路径是可行路径,即$\tau(0) = x_{init}$,$\tau(end) \in X_{goal}$且都位于非障碍物空间$X_{free}$中。
基于上述定义,运动规划问题描述为:给定三元组$\{ X,X_{free},X_{obs} \}$,出事状态点$x_{init}$和目标区域$X_{goal} \subset X_{free}$,找到一条可行路径$\tau \in X_{free}$满足$\tau(0) = x_{init}$, $\tau(end) \in X_{goal}$。
1.5 MPNet
MPNet是一个基于神经网络的运动规划器,由两个阶段组成。第一阶段对应于神经模型的离线训练。 第二个对应于在线路径生成。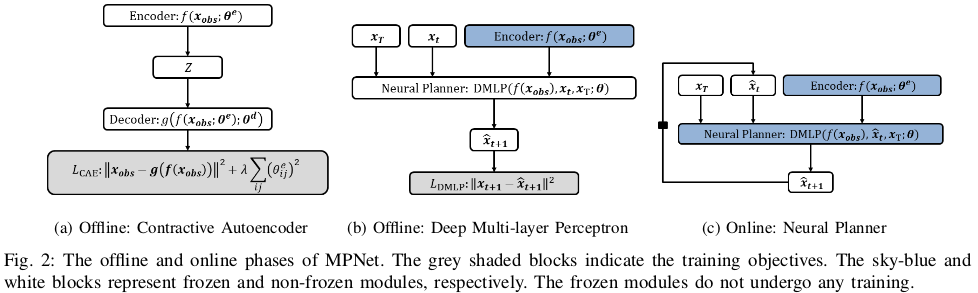
1.5.1 离线训练
两个神经网络模型:
- Contractive AutoEncoder (CAE)
- Deep Multi-Layer Perceptron(DMLP)深度多层感知器
1) Contractive AutoEncoder (CAE)
将障碍物空间$X_{obs}$编码至特征空间$Z \in \mathbb{R}^m$,编码函数,解码函数,编码器目标函数
2) Deep Multi-Layer Perceptron(DMLP)
给定$Z,x_t,x_T$,预测下一时刻状态$\hat{x}_{t+1} \in X_{free}$
使用RRT*算法在不同环境下生成的可行路径数据来训练DMLP,路径的形式是元组$\tau^* = \{ x_0, x_1, \cdots, x_T\}$。
目标函数是误差均方差函数(MSE)
1.5.2 在线路径规划
提出了一种启发式增量双向路径生成算法,生成连接起始状态和目标状态的端到端可行路径,路径生成算法:


1) Obstacles Encoder $f(x_{obs})$
离线阶段训练的CAE
2) DMPL
离线阶段训练的DMPL
3) Lazy States Contraction (LSC)
冗余点收缩。在给定路径$\tau$时,对路径进行优化,将未连接但可以直接相连的路径点进行连接。
4) Steering
steerTo函数在给定两个状态点$x_1,x_2$作为输入下,检查由两个状态点连接成的路径是否位于无障碍物空间。障碍物检测的路径点可以写成:$\tau(\delta) = (1-\delta)x_1 + \delta x_2, \delta \in [0,1]$.
5) isFeasible
给定路径$\tau = \{ x_0, x_1, \cdots, x_T\}$,判断该路径是否可行
6) Neural Planner
一种基于DMLP的启发式双向增量路径生成方法,即图中的算法2
7) Replanning
图中的算法3.给定路径$\tau = \{ x_0, x_1, \cdots, x_T\}$,若检查出该路径中存在连续两点是不可连接的,使用下面的方法重新对这两点进行规划:
- Neural Replanning
- Hybrid Replanning
1.6 实现细节
1) 数据集的生成
将一些四边形方块作为障碍物随机放置在40x40或者40x40x40的区域中成为工作空间,分别用来生成2维或3维的数据集。障碍物放置位置不同,就会生成不同的工作空间。
起始点和终止点的生成: 在工作空间的无障碍物空间中随机采样$n$个($n \in \mathbb{N}$)状态点组成一个表,再从该表中随机取出一对状态点组成起始点和终止点对。
路径生成: 利用RRT*算法生成起始点和终止点之间的可行路径,用于训练和测试。
具体细节:针对s2D、c2D、c3D情况,均生成110个不同的工作空间,在每个工作空间中再使用RRT*算法生成5000个无障碍物路径。
训练集:取100个工作空间,将每个空间中4000个路径作为训练集。
测试集:有两种:第一种,取训练集100个工作空间,将每个空间中未用于训练的200个路径作为测试集;第二种,取10个未用于训练的工作空间,将每个工作空间中2000个未用于训练的路径作为测试集。
对于Baxter的训练,使用简单环境,不包含障碍物,即不需要障碍物编码,直接使用50000个可行路径训练DMLP模型。
2) 模型结构
Contractive AutoEncoder (CAE)结构:编解码函数均由三个线性层和一个输出层构成,线性层激活函数为PReLU,解码单元和编码单元的结构刚好相反,下面主要介绍编码单元结构:
- 输入:$1400 \times d$大小的点云向量,1400是指每个维度的点数,$d \in \mathbb{N}_{\ge2}$是指工作空间的维度。
- 对于2D工作空间,输入为1400x2维,三个线性层分别包含512、256、128个隐神经元,输出为28维。即编码后的障碍物表示为$Z \in \mathbb{R}^{28}$
- 对于3D工作空间,输入为1400x3维,三个线性层分别包含786、512、256个隐神经元,输出为60维。即编码后的障碍物表示为$Z \in \mathbb{R}^{60}$
- 2D情况CAE模型构建代码:
1
self.encoder = nn.Sequential(nn.Linear(2800, 512),nn.PReLU(),nn.Linear(512, 256),nn.PReLU(),nn.Linear(256, 128),nn.PReLU(),nn.Linear(128, 28))
Deep Multi-layer Perceptron (DMLP)结构:是一个12层的深度神经网络。
- 输入: 质点或者刚体情况,输入值为编码后的障碍物$Z$、起始点和终止点配置向量三者的拼接。2D质点、3D质点和刚体的配置维度分别为2、3、3,对于Baxter机器人没考虑障碍物,所以输入只包含起始点和终止点配置向量的拼接,Baxter的配置空间维度为7。
- 中间层:前9层每一层均为线性层,激活函数为PReLU,使用Dropout,每一层神经元个数分别为:1280, 1024, 896, 768, 512, 384, 256, 256, 128;第10层和第11层不使用Dropout,神经元个数分别为64和32;第12层,即输出层,其输出的维度是配置空间的维度,比如2D质点配置空间的维度为2。
- 2D情况DMLP模型构建代码:
1
2
3
4
5
6
7
8
9
10
11
12
13self.fc = nn.Sequential(
nn.Linear(input_size, 1280),nn.PReLU(),nn.Dropout(),
nn.Linear(1280, 1024),nn.PReLU(),nn.Dropout(),
nn.Linear(1024, 896),nn.PReLU(),nn.Dropout(),
nn.Linear(896, 768),nn.PReLU(),nn.Dropout(),
nn.Linear(768, 512),nn.PReLU(),nn.Dropout(),
nn.Linear(512, 384),nn.PReLU(),nn.Dropout(),
nn.Linear(384, 256),nn.PReLU(), nn.Dropout(),
nn.Linear(256, 256),nn.PReLU(), nn.Dropout(),
nn.Linear(256, 128),nn.PReLU(), nn.Dropout(),
nn.Linear(128, 64),nn.PReLU(), nn.Dropout(),
nn.Linear(64, 32),nn.PReLU(),
nn.Linear(32, output_size))
其中input_size和output_size值分别为32,2。
3) 超参数的设置
使用Adagrad优化器,学习率0.1,Dropout参数为0.5,动量项参数为0.001。用于训练的CAE模型的工作空间有30000个。
1.7 实验结果
MPNet计算时间的平均值小于1s,与Informed-RRT*和BIT*算法相比,MPNet速度分别是它们的40和20倍。
1.8 讨论
1) Dropout导致的随机性
对于DL,在测试阶段或者在线执行阶段,通常做法是关闭Dropout。但是Dropout对路径在线生成s是有利的,因为Dropout显著提升了本模型的性能。
出现上述情况的原因分析:DMLP在重规划阶段,由Dropout引入的随机性使DMPL可以生成与之前不同的路径,下图就说明了这种特征:
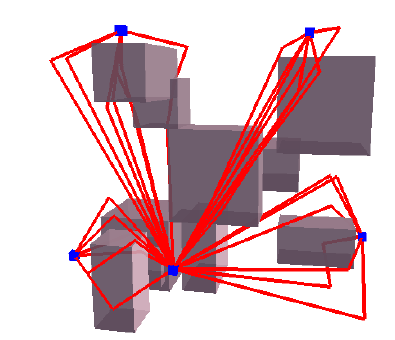
同样的起点和终点,DMLP生成了多条不同的路径,这种能力有助于路径重规划的成功,因此添加Dropout对MPNet的性能是有利的。
2) 迁移学习
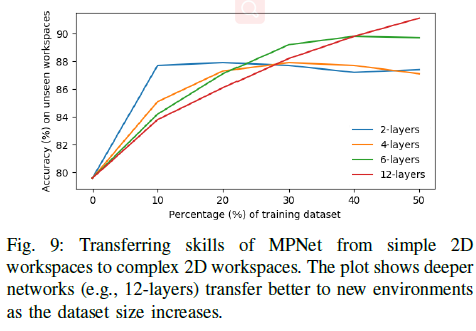
3) 完备性
因为MPNet先使用DMPL进行规划得到粗略的路径,若该路径不可行则调用重规划方法。所以MPNet的完备性取决于重规划方法是否完备,而重规划方法采用了混合经典规划方法,所以进一步可得MPNet的完备性取决于所采用的经典方法的完备性。如果经典方法采用A*算法,则MPNet是完备的;因为本文采用的是RRT*算法,所以MPNet是概率完备的。
4) 计算复杂度
。。。
1.9 结论和未来工作
未来工作:
- 将MPNet应用于动态环境,因为其有良好的泛化能力
- 增加对工作空间编码的神经注意(neural attention)
2.代码实现和复现
论文作者开源的代码可在github上下载,开源代码使用python2和pytorch实现,没有提供训练好的模型。
2.1 搭建本地开发环境
开源代码使用pytorch实现,使用Docker快速搭建pytorch环境,当然也可以通过其他方式安装pytorch环境。
Docker的使用,包括安装、gui的支持等可以参考另一篇博客:Moveit Docker的安装与配置过程
使用Docker建立pytorch环境,步骤如下:
- 拉取pytorch官方Docker镜像:
docker pull pytorch/pytorch:latest
pytorch镜像略大,需要等一会才能下载完,下载结束后通过docker image ls可以看到下载完成的镜像 创建pytorch镜像的Docker容器:
1
2
3
4
5
6
7xhost +local:root
nvidia-docker run -it \
-v /home/srn/SRn/MPNet:/workspace \
--env="DISPLAY" \
--env="QT_X11_NO_MITSHM=1" \
--volume="/tmp/.X11-unix:/tmp/.X11-unix:rw" \
pytorch/pytorch:latest bash建议新建bash文件,如run.bash,将以上命令存入bash文件中,并给定执行权限
chmod +x run.bash,然后运行./run.bash。
注意: 以上命令将本地MPNet代码目录挂载到Docker容器中,根据自己代码位置需要修改MPNet代码目录。- 进入容器后安装matplotlib库:
1
2
3apt-get updata
pip install matplotlib -i https://pypi.douban.com/simple
apt-get install python3-tk
2.2 对开源代码进行一些修改
本次主要测试MPNet部分代码,对训练数据集生成部分的代码之后在测试。由于MPNet代码使用python2编写,docker建立的环境是python3,所以要做一些修改,主要有下面的一些修改:
- 修改print函数: 使用python的
2to3函数进行修改:2to3 -w python_file - 修改整除符号
/为// - 修改包含zip函数的部分,比如data_loader.py中的
data=zip(dataset,targets),修改为data=list(zip(dataset,targets))
以上修改主要是因为python2和python3之间的差异导致的。
此外要注释掉某些python文件中的import nltk语句,这条语句导入的库并没有用上,docker容器中也没有安装这个库,所以注释掉。
2.3 训练模型
MPNet主要有两部分构成:
- Contractive AutoEncoder (CAE)
对应CAE.py - Deep Multi-Layer Perceptron(DMLP)
训练函数为train.py
所以要分别训练两个模型。主要针对2维情况下MPNet的工作进行测试,训练用的数据集使用论文作者分享的simple2D数据集,当然你也可以通过数据集生成代码自己去生成训练集,包括3维空间的规划,这是之后的工作。
将simple2D数据集下载到本地,并解压。这是本机的文件结构图:
目录中除了原始文件,其他文件有些是2to3生成的,有些是训练生成的模型文件。其中data/dataset目录是解压数据集后的目录。
2.3.1 训练CAE
按照上面的数据集修改MPNet/AE/data_loader.py中的数据路径,也可以修改CAE.py中的训练参数,然后开始训练CAE模型:python MPNET/AE/CAE.py
这一步训练耗时较短,大概15分钟。
2.3.2 训练DMLP模型
修改MPNet/data_loader.py中的数据路径和上一步生成的CAE模型数据的路径,也可以修改train.py中的训练参数,然后开始训练DMLP模型:python MPNET/train.py
这一步耗时较久,训练300个epoch在本机需要13个小时。在300个epoch后,手动终止了训练。
2.3.3 测试MPNet的效果
完成上面两步训练后就可以测试MPNet的效果了,修改neuralplanner.py中模型的路径参数。由于原代码中没有可视化函数,自己写了一个2维情况的可视化函数,主要是绘制出障碍物点云、RRT*生成的路径和MPNet生成的路径。可视化函数内容为:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24def visualize_function(i, j, g_path, a_path, a_path_length):
'''
i: i-th obstacle
j: j-th path generated by rrt*
g_path: path generated by mpnet
a_path_length: actual path length
'''
dataPath = '/workspace/data'
#绘制障碍物点云图
temp=np.fromfile(dataPath+'/dataset/obs_cloud/obc'+str(i)+'.dat') #len=2800
ob = temp.reshape(len(temp)//2,2)
#plt.plot([x[0] for x in ob], [x[1] for x in ob])
plt.scatter([x[0] for x in ob], [x[1] for x in ob])
#绘制生成的路径
plt.plot([p[0] for p in g_path], [p[1] for p in g_path],color='red',linewidth=2.5,linestyle='-')
#绘制实际路径
plt.plot([a_path[a][0] for a in range(a_path_length)],
[a_path[a][1] for a in range(a_path_length)])
plt.show()
下面是测试显示的效果图: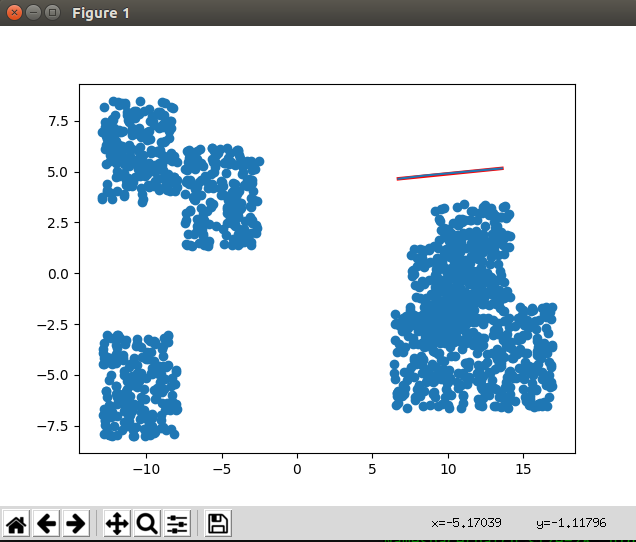
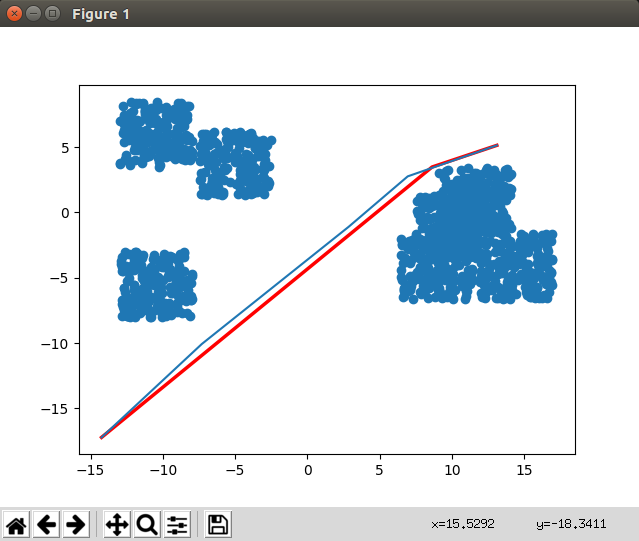
图中蓝色块是障碍物点云,蓝色路径是原始RRT*算法生成的路劲,红色路径是MPNet生成路劲,可以看到效果还不错,更多数据之后再测试。
以上修改后的代码可以参看上传到github的代码。
3.调试遇到的bug汇总
1) mpnet的python代码使用Tab缩进,如果自己修改代码使用空格缩进,混用空格和Tab缩进会导致python代码运行出现如下错误:
IndentationError: unindent does not match any outer indentation level
解决办法: 统一使用空格缩进,在vscode中使用ctrl+shift+p调出命令窗口,输入关键字“space”,找到“Convert Indentation to Spaces”功能,使用该功能就可以将当前python代码中的Tab缩进转换为空格缩进。
2) Docker使用pytorch官方提供的镜像,在安装matplotlib时(pip install matplotlib -i https://pypi.douban.com/simple),出现如下错误:
import _tkinter if this fails your python may not be configured for tk
ImportError: libX11.so.6: cannot open shared object file: No such file or directory
大概原因还是docker中gui显示的问题,google之后使用下面命令解决:apt-get install python3-tk
重要参考网站:
https://stackoverflow.com/questions/5459444/tkinter-python-may-not-be-configured-for-tk
https://stackoverflow.com/questions/25281992/alternatives-to-ssh-x11-forwarding-for-docker-containers
https://linuxmeerkat.wordpress.com/2014/10/17/running-a-gui-application-in-a-docker-container/